Generative AI Series
Ollama — Build a ChatBot with Langchain, Ollama & Deploy on Docker
Working with Ollama to run models locally, build LLM applications that can be deployed as docker containers.
This blog is an ongoing series on GenerativeAI and is a continuation of the previous blogs. In this blog series, we will explore Ollama, and build applications that we can deploy in a distributed architectures using docker.
Ollama is a framework that makes it easy to run powerful language models on your own computer. Please refer to Ollama — Brings runtime to serve LLMs everywhere. | by A B Vijay Kumar | Feb, 2024 | Medium for an introduction to Ollama. In this blog we will be building the langchain application and deploying on Docker.
Langchain Chatbot application for Ollama
Let’s build the chatbot application using Langshan, to access our model from the Python application, we will be building a simple Steamlit chatbot application. We will be deploying this Python application in a container and will be using Ollama in a different container. We will build the infrastructure using docker-compose. If you do not know how to use docker, or docker-compose, please go through some tutorials on internet, before you go any further.
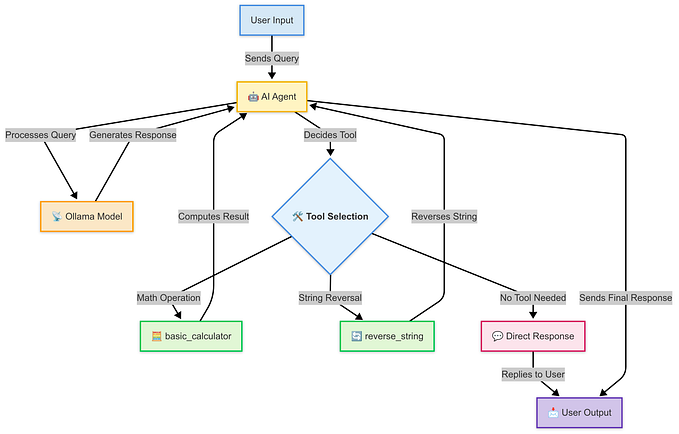
The following picture shows the architecture of how the containers interact, and what ports they will be accessing.

We will build 2 containers,
- Ollama container will be using the host volume to store and load the models (
/root/.ollamais mapped to the local./data/ollama). Ollama container will listen on 11434 (external port, which is internally mapped to 11434) - Streamlit chatbot application will listen on 8501 (external port, which is internally mapped to 8501).
Before we start coding, lets setup a Python virtual environment.
python3 -m venv ./ollama-langchain-venv
source ./ollama-langchain-venv/bin/activateThe following is the source code for streamlit application.

This is very similar source code as I have built in my previous blogs. You can refer to my other blog Retrieval Augmented Generation(RAG) — Chatbot for documents with LlamaIndex | by A B Vijay Kumar | Feb, 2024 | Medium for details on how this code works. The main difference is we are using Ollama and calling the model through Ollama Langchain library (which is part of langchain_community)
Let's define the dependencies in requirement.txt.

Let's now define a Dockerfile to build the docker image of the Streamlit application.

We are using the python docker image, as the base image, and creating a working directory called /app. We are then copying our application files there, and running the pip installs to install all the dependencies. We are then exposing the port 8501 and starting the streamlit application.
We can build the docker image using docker build command, as shown below.

You should be able to check if the Docker image is built, using docker images command, as shown below.

Let's now build a docker-compose configuration file, to define the network of the Streamlit application and the Ollama container, so that they can interact with each other. We will also be defining the various port configurations, as shown in the picture above. For Ollama, we will also be mapping the volume, so that whatever models are pulled, are persisted.

We can bring up the applications by running the docker-compose up command, once you execute docker-compose up, you should be able to see that both the containers start running, as shown in the screenshot below.

you should be able to see the containers running by executing docker-compose ps command as shown below.

We should be able to check, if ollama is running by calling http://localhost:11434, as shown in the screenshot below.

Let's now download the required model, by logging into the docker container using the docker exec command as shown below.
docker exec -it ollama-langchain-ollama-container-1 ollama run phiSince we are using the model phi, we are pulling that model and testing it by running it. you can see the screenshot below, where the phi model is downloaded and will start running (since we are using -it flag we should be able to interact and test with sample prompts)

you should be able to see the downloaded model files and manifests in your local folder ./data/ollama (which is internally mapped to /root/.ollama for the container, which is where Ollama looks for the downloaded models to serve)

Lets now run access our streamlit application by opening http://localhost:8501 on the browser. The following screenshot shows the interface

Lets try to run a prompt “generate a story about dog called bozo”. You shud be able to see the console logs reflecting the API calls, that are coming from our Streamlit application, as shown below

You can see in below screenshot, the response, I got for the prompt I sent

you can bring down the deployment by calling docker-compose down
The following screenshot shows the output

There you go. It was super fun, working on this blog getting Ollama to work with Langchain, and deploying them on Docker using Docker-Compose
Hope this was useful. I will be back with more experiments, in the meantime, have fun, and keep coding!!! see you soon!!!
you can access the full source code in my GitHub here. abvijaykumar/ollama-langchain (github.com)
References